Vraag 6: Keuze test (Leesopdracht)
Vorige les losten jullie deze onderzoeksvraag op met behulp van parametrische ANOVA (de F-test). Dit is een geldige test als aan een aantal assumpties voldaan worden die geverifieerd moeten worden in de dataset. Echter, hoe kleiner de dataset hoe moeilijker het is om deze assumptie te controleren. Laten we als voorbeeld kijken naar de asumptie van normaliteit.
qqplot1
qqplot2
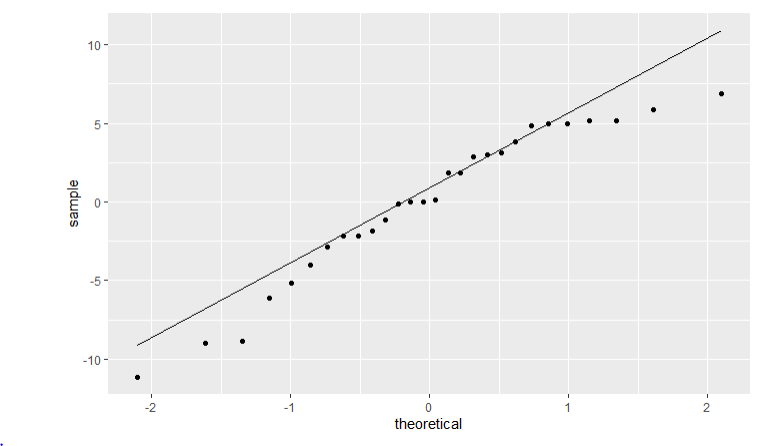
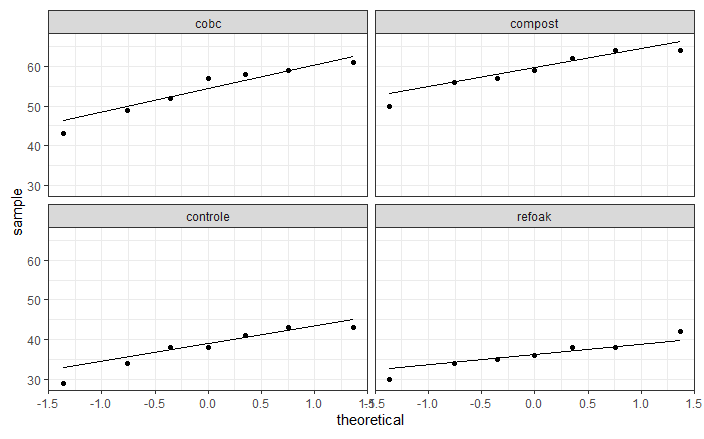
De QQ-plot is nogal twijfelachtig, en men zou beide kanten kunnen beargumenteren. Inderdaad, enerzijds kan men argumenteren dat de QQ-plot niet bijzonder sterk afwijkt van wat men zou verwachten op basis van een Normale distributie. Dit geldt zowel voor de QQ-plot van de residuen als voor de QQ-plots in de aparte groepen. Anderzijds, kan men argumenteren dat (i) de QQ-plot bij de residuen wel degelijk licht afwijkt, en (ii) de QQ-plots binnen elke groep weinig bewijs leveren voor normaliteit, aangezien er zo weinig datapunten in elke groep zitten.
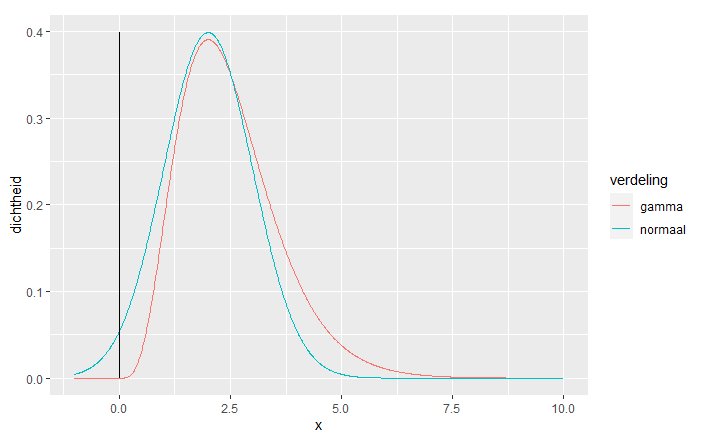
Ter vergelijking zullen we onze steekproef vergelijken met simulaties uit een normale verdeling en een gamma verdeling. Een gamma distributie heeft een aantal eigenschappen die een betere zijn om gewichten te modelleren. Bijvoorbeeld, gewichten kunnen niet negatief zijn, een normale distributie kan tot min oneindig lopen waar een gamma distributie een ondergrens heeft bij nul.
We tonen eerst visueel het verschil tussen de normale verdeling en de gamma verdeling
x= seq(-1,10,.01)
data1<-data.frame(x ,normaal = dnorm(x,2),gamma = dgamma(x,5,2))
data2<-data1%>%gather(verdeling, dichtheid, normaal:gamma)
density_plot<-data2%>%ggplot(aes(x=x, y=dichtheid, col=verdeling))+
geom_line()+
geom_line(aes(x=0), color="black")
density_plot
We zullen nu zowel steekproeven genereren uit een normale verdeling en een gamma verdeling met dezelfde grootte als onze oorspronkelijke steekproef.
set.seed(1)
#Normale verdeling
data1<-data.frame(versgewicht_sim=rnorm(28),behandeling_sim=as.factor(rep(1:4,7)))
model1<-lm(versgewicht_sim~behandeling_sim, data=data1)
qqplot1_sim<-ggplot(mapping=aes(sample=model1$residuals))+
geom_qq()+geom_qq_line()+theme_bw()
qqplot1_sim
qqplot2_sim<-data1%>%ggplot(aes(sample=versgewicht_sim))+
geom_qq()+geom_qq_line()+facet_wrap(~behandeling_sim)+theme_bw()
qqplot2_sim
#Gamma verdeling
data1<-data.frame(versgewicht_sim=rgamma(28,5,2),behandeling_sim=as.factor(rep(1:4,7)))
model1<-lm(versgewicht_sim~behandeling_sim, data=data1)
qqplot1_sim<-ggplot(mapping=aes(sample=model1$residuals))+
geom_qq()+geom_qq_line()+theme_bw()
qqplot1_sim
qqplot2_sim<-data1%>%ggplot(aes(sample=versgewicht_sim))+
geom_qq()+geom_qq_line()+facet_wrap(~behandeling_sim)+theme_bw()
qqplot2_sim
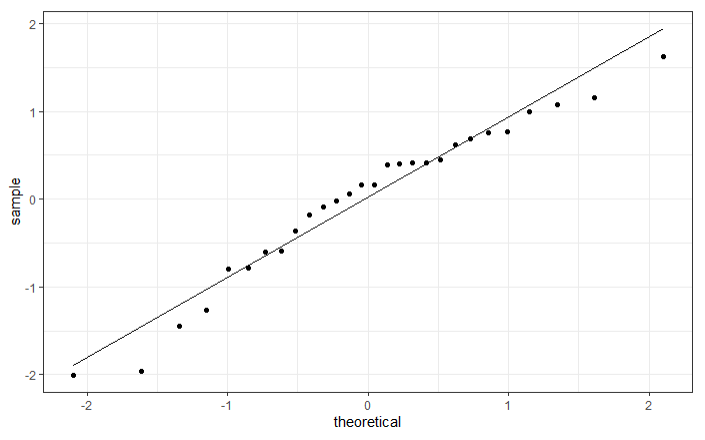
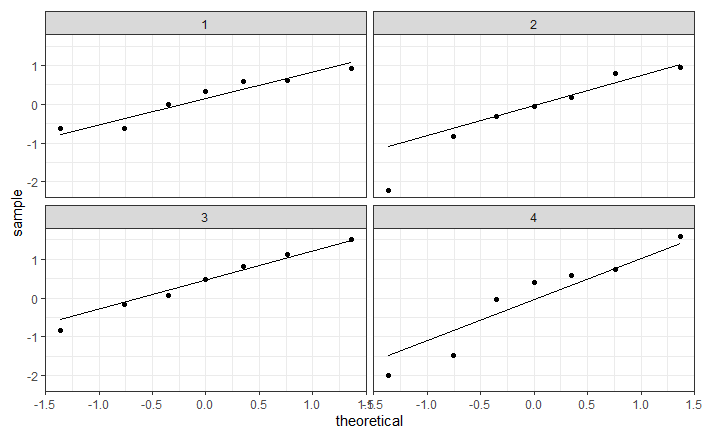
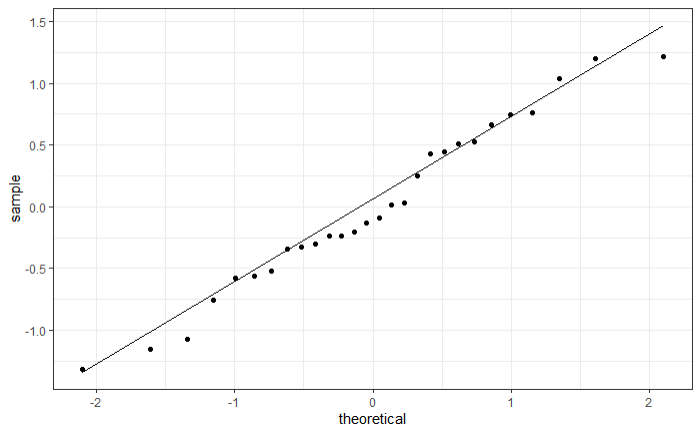
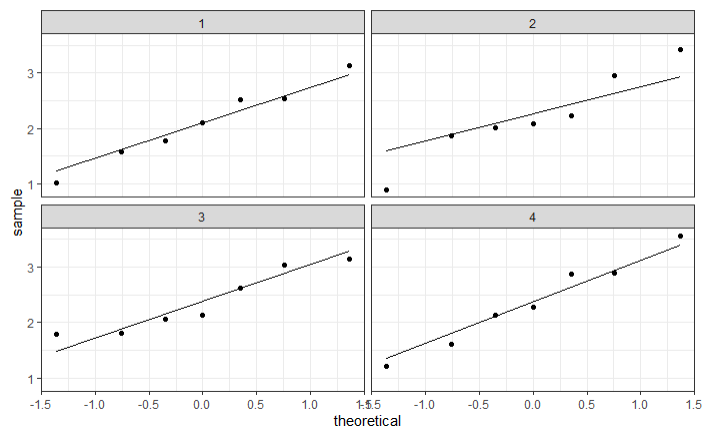
Uit de simulaties blijkt dat we onze gegevens niet kunnen onderscheiden van normaal verdeelde gegevens, maar bijvoorbeeld ook niet van gamma verdeelde gegevens. We hebben dus geen bewijs dat de data niet normaal verdeeld zijn, maar zeker ook geen bewijs dat ze wél normaal verdeeld zijn. Aangezien we hier ook te weinig gegevens hebben om gebruik te maken van de Centrale limietstelling, zijn we niet zeker of de resultaten van ANOVA betrouwbaar zullen zijn.
Zoals je ziet, is dit een dataset waarbij zowel de argumentatie voor een parametrische ANOVA test als de argumentatie voor een niet-parametrische test steek kan houden.