Vraag 12: Assumpties – Normaliteit, conclusie (leesopdracht)
De QQplots in figuur 2 lijken te suggereren dat de metingen binnen iedere behandelingsgroep normaal verdeeld zijn. Echter, QQplots zullen veelal normaliteit suggereren bij weinig datapunten.
Een tweede controle zou de distributie van de residuen van het lineair model kunnen zijn. Deze moeten namelijk ook normaal verdeeld zijn als de data per behandelingsgroep normaal verdeeld is.
plot(fit, which = 2,col = fit$model$behandeling)
legend('bottomright', levels(fit$model$behandeling), text.col = 1:4)
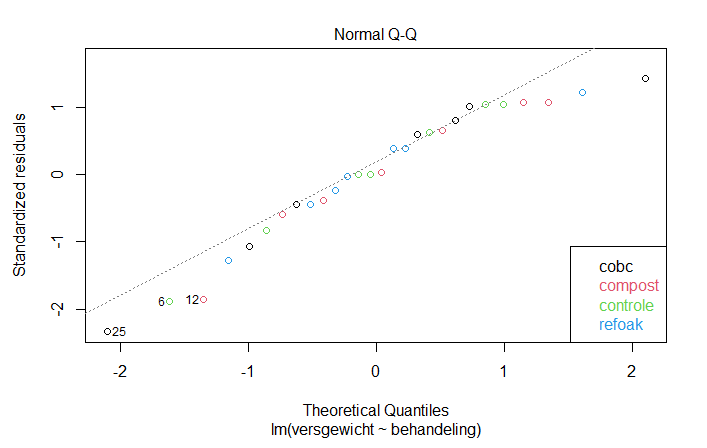
De qq-plot suggereert dat de residuen ietswat scheef verdeeld zijn naar links. 28 datapunten is echter nog altijd niet bijzonder veel. Deze qqplot zou men dan ook kunnen verwachten wanneer de data uit een normale distributie zou komen. We zullen voor deze oefening aannemen dat de data normaal verdeeld is.