We will now try to predict per capita crime rate (crim) in the Boston data set.
Questions
-
We’ll try out some of the regression methods explored in this chapter, such as best subset selection, the lasso, ridge regression and PCR.
-
Which model (or set of models) seems to perform well on this data set? Make sure that you are evaluating model performance using validation set error, cross-validation, or some other reasonable alternative, as opposed to using training error!
-
Does your chosen model involve all of the features in the data set?
Let’ start with best subset selection.
library(MASS) data(Boston) set.seed(1) predict.regsubsets <- function(object, newdata, id, ...) { form <- as.formula(object$call[[2]]) mat <- model.matrix(form, newdata) coefi <- coef(object, id = id) xvars <- names(coefi) mat[, xvars] %*% coefi } k = 10 folds <- sample(1:k, nrow(Boston), replace = TRUE) cv.errors <- matrix(NA, k, 13, dimnames = list(NULL, paste(1:13))) for (j in 1:k) { best.fit <- regsubsets(crim ~ ., data = Boston[folds != j, ], nvmax = 13) for (i in 1:13) { pred <- predict(best.fit, Boston[folds == j, ], id = i) cv.errors[j, i] <- mean((Boston$crim[folds == j] - pred)^2) } } mean.cv.errors <- apply(cv.errors, 2, mean) plot(mean.cv.errors, type = "b", xlab = "Number of variables", ylab = "CV error")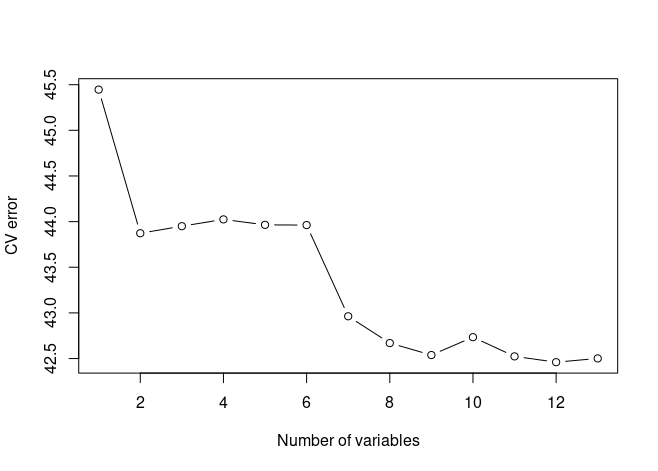
Based on the plot, how many independent variables should the optimal model contain? Store the number in
bestsubset.size.For the following tasks, always set a seed value of 1.
Next, consider lasso regression. Use cross-validation and MSE as measure for it. Store the optimal lambda in
bestlambda.lasso. Extract the CV estimate for the test MSE from the output of thecv.glmnetfunction (that you may have calledcv.outfor example) and store incverror.lasso.Next, examine ridge regression, which is fairly similar in terms of syntax to lasso regression. Follow the same steps as with lasso above and store the corresponding
bestlambda.ridgeandcverror.ridge.Finally, try out PCR on the Boston data set. Store the CV estimate for test MSE with no dimension reduction in
pcr.mse.nored.
Assume that:
- The
MASSlibrary has been loaded - The
Bostondataset has been loaded and attached - The
glmnetlibrary has been loaded - The
plslibrary has been loaded