NHANES: Lengte
Empirische distributie
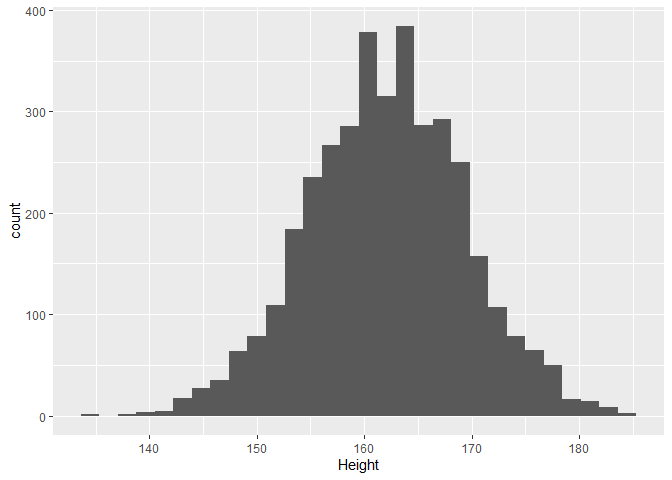
We kunnen de distributie van de lengte voor volwassen vrouwen schatten aan de hand van het histogram.
NHANES %>%
filter(Gender=="female"&!is.na(Height)&Age>18) %>%
ggplot(aes(x=Height)) +
geom_histogram()
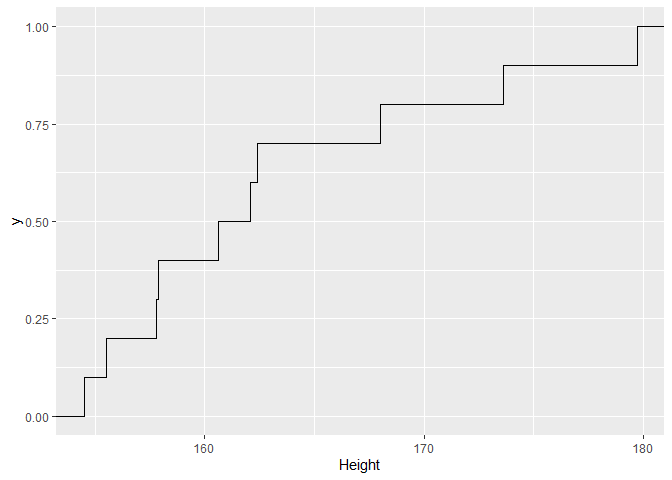
We kunnen de cumulative distributie functie schatten door gebruik te maken van de empirische cumulatieve distributie functie.
- Elke observatie werd één keer geobserveerd in het staal.
- Dus empirische cumulatieve distributie functie van het staal is een discrete distributie met probabiliteit 1/n op elke observatie.
- De empirische cumulatieve distributie functie (ECDF) is gegeven door
NHANES %>%
filter(Gender=="female"&!is.na(Height)&Age>18) %>%
ggplot(aes(x=Height)) +
stat_ecdf()

We kunnen de empische cumulatieve distributie functie gebruiken om kansen te berekenen. Wat is de kans dat een vrouw kleiner is dan 150 cm.
ecdfFem <- NHANES %>%
filter(Gender=="female"&!is.na(Height)&Age>18) %>%
pull("Height") %>%
ecdf
ecdfFem(150)
## [1] 0.05222073
We illustreren dit ook voor een steekproef van grootte 10
set.seed(502)
fem10<- NHANES %>%
filter(Gender=="female"&!is.na(Height)&Age>18) %>%
sample_n(size=10)
fem10 %>%
ggplot(aes(x=Height)) +
stat_ecdf()
ecdfFem10 <- fem10 %>%
pull(Height) %>%
ecdf
ecdfFem10(150)
## [1] 0
Merk op dat die kans niet goed wordt geschat o.b.v. de kleine steekproef. Er zijn immers te weinig observaties om de kansen goed te kunnen schatten.
Merk ook op dat we die kans ook hadden kunnen schatten door te berekenen hoeveel lengtemetingen er lager zijn dan 150.
NHANES %>%
filter(Gender=="female"&!is.na(Height)&Age>18) %>% count(Height <=150) %>%
mutate(prob=n/sum(n))
## # A tibble: 2 x 3
## `Height <= 150` n prob
## <lgl> <int> <dbl>
## 1 FALSE 3521 0.948
## 2 TRUE 194 0.0522
ecdfFem(150)
## [1] 0.05222073
fem10 %>%
count(Height <=150) %>%
mutate(prob=n/sum(n))
## # A tibble: 1 x 3
## `Height <= 150` n prob
## <lgl> <int> <dbl>
## 1 FALSE 10 1
ecdfFem10(150)
## [1] 0
Normale benadering
In de introductie zagen we dat de lengte metingen een mooie klokvorm hadden. We kunnen dus aannemen dat de metingen approximatief normaal verdeeld zijn. We zullen dat in hoofdstuk 4 Data Exploratie illustreren a.d.h.v. diagnostische plots.
-
We kunnen de verdeling van de lengte metingen ook benaderen d.m.v. een normale distribution.
-
We moeten hiervoor enkel twee parameters schatten:
- gemiddelde via steekproefgemiddelde (\(\hat\mu=\bar x\))
- variantie via steekproefvariantie (\(\hat{\sigma}^2= s^2\)) of de standaardafwijking d.m.v. steekproef standaarddeviatie (\(\hat\sigma=s\)).
HeightSum <- NHANES %>%
filter(Gender=="female"&!is.na(Height)&Age>18) %>%
summarize(mean=mean(Height),sd=sd(Height))
HeightSum
## # A tibble: 1 x 2
## mean sd
## <dbl> <dbl>
## 1 162. 7.27
We zien dat de benadering goed werkt:
NHANES %>%
filter(Gender=="female"&!is.na(Height)&Age>18) %>%
ggplot(aes(x=Height)) +
geom_histogram(aes(y=..density.., fill=..count..)) +
xlab("Lengte (cm)") +
stat_function(
fun=dnorm,
color="red",
args=list(
mean=HeightSum$mean[1],
sd=HeightSum$sd[1]
)
)

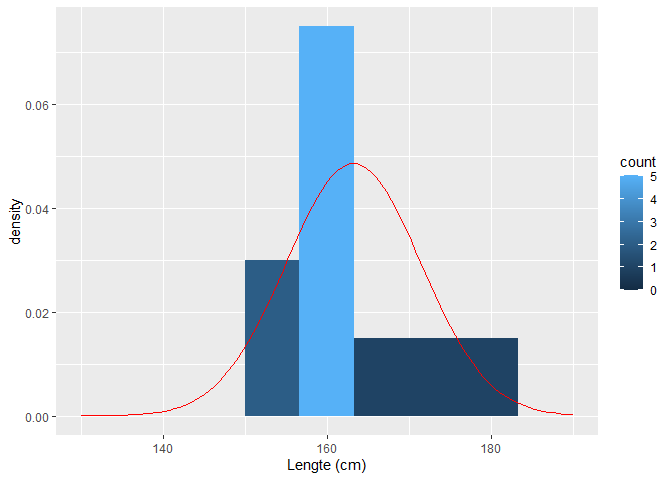
We doen nu hetzelfde op basis van de steekproef met de 10 vrouwen.
HeightSum10 <- fem10 %>%
summarize(mean=mean(Height),sd=sd(Height))
HeightSum10
## # A tibble: 1 x 2
## mean sd
## <dbl> <dbl>
## 1 163. 8.19
fem10 %>%
ggplot(aes(x=Height)) +
geom_histogram(aes(y=..density.., fill=..count..),bins=10) +
xlab("Lengte (cm)") +
stat_function(
fun=dnorm,
color="red",
args=list(
mean=HeightSum10$mean[1],
sd=HeightSum10$sd[1]
)
) +
xlim(130,190)
We kunnen de normale benadering nu ook gebruiken om de kans te berekenen dat een vrouw kleiner is dan 150 cm: Pr(X <= 150).
We doen dit op basis van de volledige steekproef en vergelijken dit uit wat we bekomen met de ECDF.
pnorm(150,HeightSum$mean[1],HeightSum$sd[1])
## [1] 0.0484516
ecdfFem(150)
## [1] 0.05222073
Op basis van de kleine steekproef bekomen we:
pnorm(150,HeightSum10$mean[1],HeightSum10$sd[1])
## [1] 0.05346615
ecdfFem10(150)
## [1] 0
Voor kleine steekproef is geschatte kans o.b.v. empirische distributie
veel minder nauwkeurig. Kwantielen geschat o.b.v. kleine steekproef zijn
immers vrij onzeker. Ze gebruiken immers maar een fractie van de data.
De schatting o.b.v. de normale verdeling laat toe om alle data te
gebruiken voor het schatten van de model parameters en is daarom
nauwkeuriger. Uiteraard heeft de laatste aanpak de beperking dat de data
Normaal verdeeld moeten zijn.