Data Understanding in Text Mining
In this exercise, we will perform text mining using the tm and stringr packages. Text mining is a process of extracting meaningful information from text data. It is a crucial step in many data science projects, especially those involving natural language processing.
We will use the stringr package for basic text manipulation. It is a more coherent and fast alternative to base R. For every basic R regular expression command, there is a stringr alternative. You can find more information here1.
Dataset
The productreviews dataset contains customer reviews of Amazon products.
The data is collected using the read_delim function from the readr package of tidyverse.
Each row in the dataset represents a single review.
reviews <- read_delim("productreviews.csv", delim = "\n", col_names = FALSE)
Understanding the Data
First, let’s look at the first few reviews.
The str_sub function is used to display the first 50 characters of each review.
reviews %>% pull(X1) %>% str_sub(1,50)
[1] "Two month-long trips abroad: this is the best. It " "This is nearly as heavy as my laptop and I was hop"
[3] "Wonderfully thin, light, and durable. The keyboard" "This Keyboard/case cover is Absolutely FABULOUS!!!"
[5] "Great case! Easy to use, thin, and turns my iPad i"
Next, we will analyze the length of the reviews.
The nchar function is used to count the number of characters in each review.
The results are displayed in a histogram.
hist(nchar(reviews$X1), main="Number of characters per product review")
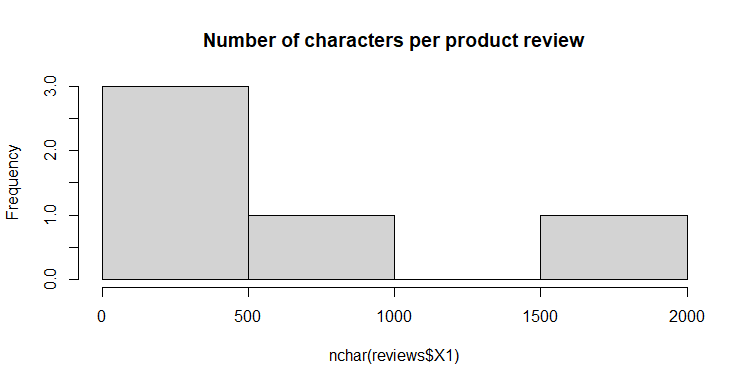
From this histogram, it becomes clear that most of the reviews contains 500 characters or less.
We can also count the number of words in each review.
The str_split function is used to split the reviews into words, and the length function is used to count the words.
hist(map_int(str_split(reviews$X1," "),length), main="Number of words per product review")
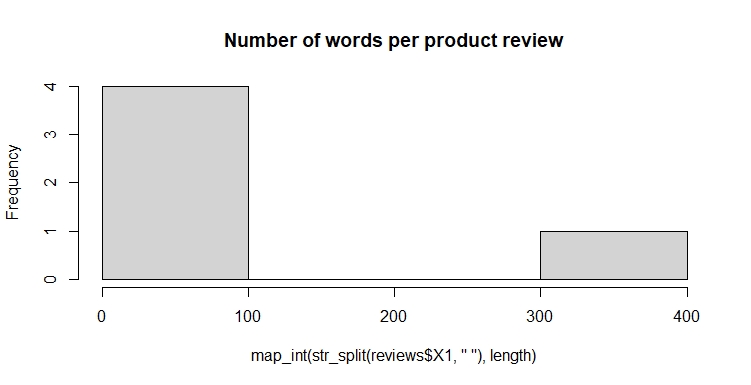
From this histogram, it becomes clear that most of the reviews contains 100 words or less.
Exercise 1
Calculate how many reviews are present in the dataset and store it as n_reviews.
Exercise 2
Calculate how many times the word "good" occurs in all product review and
store it as n_good.
To download the productreviews dataset click
here2.
Assume that:
- The
productreviewsdataset is given. - The stringr package is loaded.