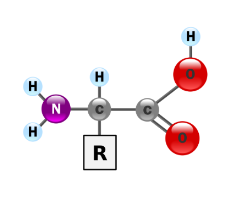
Menselijke eiwitten worden opgebouwd uit 20 verschillende aminozuren. Dit zijn organische verbindingen die allemaal dezelfde generische chemische structuur hebben die hieronder staat weergegeven. De zijketen R is voor elk van de aminozuren verschillend en de polariteit van deze zijketen bepaalt in grote mate de oplosbaarheid van de aminozuren. De gangbare indeling van de aminozuren in zes grote groepen wordt weergegeven in onderstaande tabel. Deze indeling gebeurt op basis van de algemene structuur van de aminozuren en de chemische eigenschappen van hun R-zijketens. Elk aminozuur wordt doorgaans aangeduid met een hoofdletter (hierbij worden alle letters van het alfabet gebruikt, behalve B, J, O, U, X en Z). In de tabel hebben we dan ook zowel de namen als de corresponderende hoofdletters van de aminozuren opgenomen.
| Klasse | Naam | Letters |
|---|---|---|
| alifatisch | glycine, alanine, leucine, valine, isoleucine | G, A, L, V, I |
| hydroxyl | serine, cysteïne, threonine, methionine | S, C, T, M |
| cyclisch | proline | P |
| aromatisch | fenylalanine, tyrosine, tryptofaan | F, Y, W |
| basisch | histidine, lysine, arginine | H, K, R |
| zuur | asparaginezuur, glutaminezuur, asparagine, glutamine | D, E, N, Q |
Opgave
Elke regel van het tekstbestand proteins.txt bevat de stringvoorstelling van een eiwitsequentie, die bestaat uit een reeks hoofdletters die de aminozuren voorstellen. Daarna volgt telkens één enkele spatie en een woord dat enkel uit hoofdletters bestaat. Gevraagd wordt:
-
Bepaal reguliere expressies voor elk van onderstaande verzamelingen. Daarbij staat $$\mathcal{P}$$ voor de verzameling van alle eiwitsequenties. Probeer de reguliere expressies bovendien zo kort mogelijk te houden.
-
$$\alpha = \{ p \in \mathcal{P}\,|\,$$ in $$p$$ staat na elk alifatisch aminozuur een basisch aminozuur $$\}$$
voorbeelden: DGHEHMVHQHGRHDQSLHNR $$\in \alpha$$CLMNIMRNKENKYTRCNDWINWNTMQ $$\not\in \alpha$$ -
$$\beta = \{ p \in \mathcal{P}\,|\,$$ als er in $$p$$ tussen twee zure aminozuren één ander aminozuur staat, dan moet dit een basisch aminozuur zijn $$\}$$
voorbeelden: ALMQRNTVKYHCYFNHNRGTMDRQFYAK $$\in \beta$$LLVRKFDIDHHQFSVLWDHDQEHAIAKIKCVQKNIYVMPM $$\not\in \beta$$ -
$$\gamma = \{ p \in \mathcal{P}\,|\,$$ in $$p$$ staat voor en na elk aminozuur met een hydroxylgroep altijd hetzelfde aromatisch aminozuur $$\}$$
voorbeelden: HRVRAHGHDFNIYMYIKQHFLFSFNKWWNEIWTWVRHGKHIKFARRGFCFHFYE $$\in \gamma$$EDARAIDPKRSMRIHNKNRWCGYRIHTQALFLKYAFMKRFWVGI $$\not\in \gamma$$ -
$$\delta = \{ p \in \mathcal{P}\,|\,$$ $$p$$ bevat minstens één triplet dat meer dan één keer voorkomt $$\}$$
opmerking: de herhaalde tripletten mogen elkaar ook gedeeltelijk overlappen
voorbeelden: EDGFYSFPCPQILQDVGEINAFCHLNMKEEKSRYVFPCRAVSECREFKKLCKEWMG $$\in \delta$$GCYTFTFQTKALDDNKHMNVFCIFQDCFHYFEFRSMADVYDRANAINCLDPFDFSV $$\not\in \delta$$
Gebruik een commando uit de grep familie om enkel die regels van het bestand proteins.txt te selecteren, waarvan het patroon behoort tot de opgegeven verzameling.
-
-
Beschouw de verzamelingen $$\alpha$$, $$\beta$$, $$\gamma$$ en $$\delta$$ zoals hierboven gedefinieerd. Gebruik nu deze verzamelingen om op de volgende manier een boodschap bestaande uit vier woorden te achterhalen:
-
Het eerste woord staat op unieke regel met het patroon uit de verzameling $$\alpha \cap \beta$$
-
Het tweede woord staat op unieke regel met het patroon uit de verzameling $$\beta \cap \gamma$$
-
Het derde woord staat op unieke regel met het patroon uit de verzameling $$\gamma \cap \delta$$
-
Het vierde woord staat op unieke regel met het patroon uit de verzameling $$\delta \cap \alpha$$
Geef telkens een Unix commando dat elk van deze woorden opzoekt in het bestand en uitschrijft naar standaard uitvoer (zonder het patroon dat aan het woord voorafgaat). Hierbij is het dus niet toegelaten om het woord letterlijk uit te schrijven (bv. echo xxx).
-