Het geometrische gemiddelde van een reeks waarnemingen \(x_i, i=1, 2, \dots, n\) ontstaat door er de natuurlijke logaritme van te berekenen, het gemiddelde hiervan te nemen en dit vervolgens terug te transformeren naar de originele schaal door er de exponentiële functie van te nemen:
\[\begin{equation*} \sqrt[n]{\prod\limits_{i=1}^n x_i} = \exp\left\{\frac{1}{n} \sum_{i=1}^n \log(x_i)\right\} \end{equation*}\]Einde definitie
-
Geometrisch gemiddelde ligt dichter bij de mediaan dan het gemiddelde
-
log-transformatie verwijdert scheefheid
-
Is vaak een meer geschikte maat voor centrale locatie dan de mediaan:
- Gebruikt alle observatie: is meer precies
- Is het rekenkundig gemiddelde van log-transformeerde data \(\rightarrow\) klassieke statistische methoden kunnen direct worden gebruikt, b.v. hypothese testen en betrouwbaarheidsintervallen (zie hoofdstuk 5)
- Veel biologische en chemische variabelen zoals concentraties, intensiteiten, etc kunnen niet negatief zijn.
- Verschillen op log schaal hebben de betekenis van een
log fold change:
-
In Genomics wordt de \(\log_2\) transformatie veel gebruikt.
-
Een verschil van 1 op \(\log_2\) schaal betekent een verdubbeling op de originele schaal \(FC=2\).
logSummary <-
NHANES %>%
filter(Gender=="female") %>%
summarize(
logMean = mean(BMI %>% log2,na.rm=TRUE),
sd = sd(BMI %>% log2,na.rm=TRUE),
mean = mean(BMI,na.rm=TRUE),
median = median(BMI,na.rm=TRUE)
) %>%
mutate(geoMean=2^logMean)
NHANES %>%
filter(Gender=="female") %>%
ggplot(aes(x=BMI %>% log2)) +
geom_histogram(
aes(y=..density.., fill=..count..),
bins=30) +
geom_density() +
stat_function(fun=dnorm,
color="red",
args=list(
mean=logSummary$logMean,
sd=logSummary$sd)
)
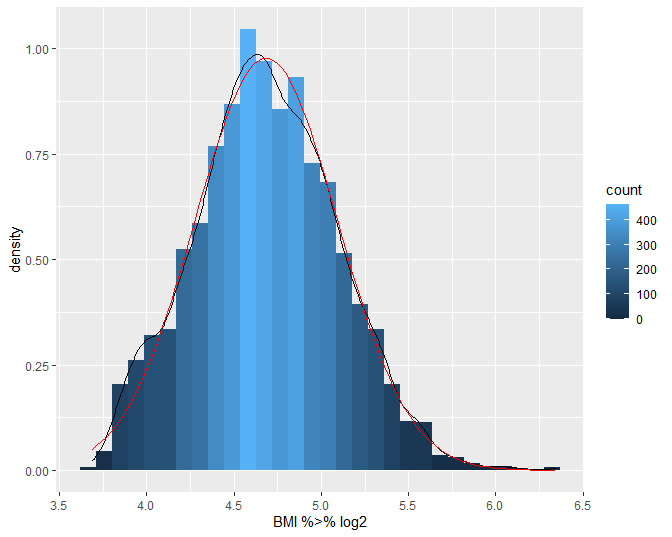
Figuur 7: Boxplot van BMI en log(BMI) in de NHANES studie.
logSummary
## # A tibble: 1 x 5
## logMean sd mean median geoMean
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 4.68 0.408 26.8 25.6 25.7
In situaties waar de log-transformatie inderdaad de scheefheid wegneemt, zal het geometrisch gemiddelde dichter bij de mediaan liggen dan het gemiddelde. Wanneer de verdeling scheef is, is ze soms zelfs een nuttigere maat voor centrale locatie dan de mediaan:
-
omdat ze ook gebruik maakt van de exacte waarden van de observaties en daarom doorgaans preciezer is dan de mediaan;
-
omdat ze, op een transformatie na, berekend wordt als een rekenkundig gemiddelde (weliswaar van de logaritmisch getransformeerde observaties) en algemene statistische technieken voor een gemiddelde (zoals betrouwbaarheidsintervallen (zie volgende hoofdstukken) en toetsen van hypothesen (zie volgende hoofdstukken) daardoor vrijwel rechtstreeks toepasbaar zijn voor geometrische gemiddelden.
Het gemiddelde en mediane BMI bedraagt 26.66 en 25.98 , respectievelijk. Het gemiddelde is hier groter dan de mediaan omdat de BMI scheef verdeeld is naar rechts (zie Figuur 7). De verdeling wordt meer symmetrisch na log-transformatie. Het gemiddelde en mediane log-BMI liggen ook dichter bij elkaar en bedragen respectievelijk 3.25 en 3.26. De geometrisch gemiddelde BMI-concentratie bekomen we door de exponentiële functie te evalueren in 3.25, hetgeen ons 25.69 oplevert. Merk op dat dit inderdaad beter met de mediaan overeenstemt dan het rekenkundig gemiddelde.
Einde voorbeeld
Tot slot, vooraleer een eenvoudige maat voor de centrale ligging (en spreiding) te construeren of interpreteren, is het goed om altijd eerst de volledige verdeling te bekijken! Immers, stel dat men het gemiddelde of mediaan berekent van gegevens uit een bimodale verdeling (d.i. een verdeling met 2 modi, voor bvb. zieken en niet-zieke dieren). Dan kan het gemiddelde of mediaan makkelijk een zeer zeldzame waarde aannemen die geenszins in de buurt van 1 van beide maxima ligt.