Afwijkingen van Modelveronderstellingen
De primaire onderstelling in lineaire regressie-analyse is de aanname dat de uitkomst lineair varieert in de predictor. Wanneer residuplots suggereren dat aan deze onderstelling niet is voldaan, dan kan men overwegen om de verklarende variabele te transformeren. In genexpressie studies waarbij expressie als een covariaat wordt gebruikt om een andere variabele te verklaren, is het bijvoorbeeld vaak zo dat de (gemiddelde) uitkomst niet lineair varieert in functie van de predictor, maar wel in functie van het logaritme van de genexpressie. In dat geval kan men ervoor kiezen om de log-transformatie van de verklarende variabele als predictor in het model op te nemen. Vaak wordt in expressie studies een \(\log_2\) transformatie gebruikt. In andere voorbeelden kan een andere transformatie dan de log-transformatie beter geschikt zijn, zoals de vierkantswortel (\(\sqrt{x}\)) of inverse (\(1/x\)) transformatie.
Een transformatie van de verklarende variabele is vaak makkelijk uit te voeren, maar bemoeilijkt wel vaak de interpretatie van de parameters in het model. Dit laatste is echter niet het geval wanneer de log-transformatie wordt gebruikt, een stijging in \(log_2\)-expressie met bijvoorbeeld 1 eenheid is immers equivalent met een wijziging in genexpressie met een factor \(2^1=2\). Kenmerkend aan transformatie van de verklarende variabele is dat ze geen rechtstreekse invloed heeft op de homogeniteit van de variantie en de Normaliteit van de uitkomst (bij vaste waarden van de predictorvariabele), tenzij door het verbeteren van de lineariteit van het model. Om die reden is deze optie vaak minder geschikt wanneer er sterke afwijkingen van Normaliteit zijn.
Een alternatieve mogelijkheid om de lineariteit van het model te verbeteren, is hogere orde regressie (in het Engels: higher order regression. Hierbij modelleert men rechtstreeks niet-lineaire relaties door hogere orde termen in het model op te nemen. Zo kan men bijvoorbeeld een tweede orde model beschouwen:
\[E(Y|X)=\beta_0+\beta_1X+\beta_2X^2\]zodat de regressiekromme eruit ziet als een parabool, of een derde orde model:
\[E(Y|X)=\beta_0+\beta_1X+\beta_2X^2+\beta_3X^3\]zodat de regressiekromme een derdegraadspolynoom is. Deze methode kan gezien worden als een vorm van transformatie van de verklarende variabele en bezit wezenlijk dezelfde eigenschappen en voor- en nadelen. Een bijkomend voordeel is echter dat het hier niet nodig is om zelf een transformatie te zoeken, maar dat de methode zelf impliciet een goede polynoom als transformatie schat.
Tenslotte kan men ook overwegen om, in plaats van de verklarende variabele, de uitkomst te transformeren. Bijvoorbeeld, wanneer de uitkomsten scheef verdeeld zijn naar rechts is het vaak aangewezen om een log-transformatie van de uitkomst uit te voeren en deze nieuwe variabele als uitkomst in het model op te nemen. Doorgaans verbetert dit niet alleen de lineariteit van het model, maar maakt het ook de residu’s beter Normaal verdeeld met een meer constante variabiliteit. Deze methode heeft dezelfde voor- en nadelen als transformatie van de verklarende variabele. Een groot verschil dat de keuze tussen beide methoden beïnvloedt is dat transformaties van de onafhankelijke variabele weinig of geen invloed hebben op de verdeling van de residu’s (tenzij via wijzigingen in hun gemiddelde) in tegenstelling tot transformaties van de afhankelijke variabele. In het bijzonder blijven Normaal verdeelde residu’s vrij Normaal verdeeld na transformatie van de verklarende variabele, terwijl ze mogelijks niet langer Normaal verdeeld zijn na transformatie van de uitkomst, en vice versa.
In het borstkanker voorbeeld wordt de S100A8 genexpressie gemodelleerd in functie van de ESR1 genexpressie. Er waren problemen m.b.t. heteroscedasticiteit, mogelijkse afwijking van normaliteit (scheefheid naar rechts), negatieve concentratievoorspellingen die theoretisch niet mogelijk zijn en niet-lineairiteit. Dergelijke problemen treden veelal op bij concentratie en intensiteitsmetingen. Deze zijn vaak log-normaal verdeeld (normale verdeling na log-transformatie) en worden daarom vaak log-getransformeerd. Bovendien zagen we in Figuur 27 eveneens een soort exponentiële trend. In de genexpressie literatuur wordt veelal gebruik gemaak van \(\log_2\) transformatie gezien een verschil van 1 op log-schaal een verdubbeling impliceert in de expressie op de originele schaal. Wanneer men gen-expressie op log-schaal modelleert, modellert men dus in feite proportionele verschillen op de originele schaal wat ook meer relevant is vanuit een biologisch standpunt.
In deze sectie zullen we beide genexpressies \(\log_2\) transformeren en een log-lineaire regressie uitvoeren. Zoals we zullen zien vormen de outliers in de S100A8 expressie na log-transformatie ook geen problemen meer.
brca <- brca %>%
mutate(
log2S100A8 = log2(S100A8),
log2ESR1 = log2(ESR1)
)
lm2 <- lm(log2S100A8 ~ log2ESR1, brca)
brca %>%
ggplot(aes(x = log2ESR1, y = log2S100A8)) +
geom_point() +
geom_smooth(se = FALSE, col = "grey") +
geom_smooth(method = "lm", se = FALSE)

Figuur 31: Scatterplot voor log2-S100A8 expressie in functie van de log2-ESR1 expressie met smoother en lineair model die het verband tussen beide genen samenvatten (outliers worden niet langer verwijderd uit de dataset).
In Figuur 31 zien we duidelijk een dalende lineaire trend van de S100A8 expressie i.f.v. de ESR1 expressie na log-transformatie. De smoother toont ook niet langer een afwijking aan van lineariteit. Daarnaast kunnen we alle data meenemen in de analyse en kan het model geen negatieve expressiewaarden meer voorspellen na terugtransformatie. In Figuur 32 zien we tevens dat er niet langer afwijkingen zijn van lineariteit, normaliteit en gelijkheid van variantie. De residuen in de residu-plot liggen mooi rond nul en hebben een constante spreiding. De QQ-plot toont geen systematische afwijkingen van normaliteit en de plot links beneden toont ook geen trend in de variantie van de residuen.
par(mfrow=c(2,2))
plot(lm2)
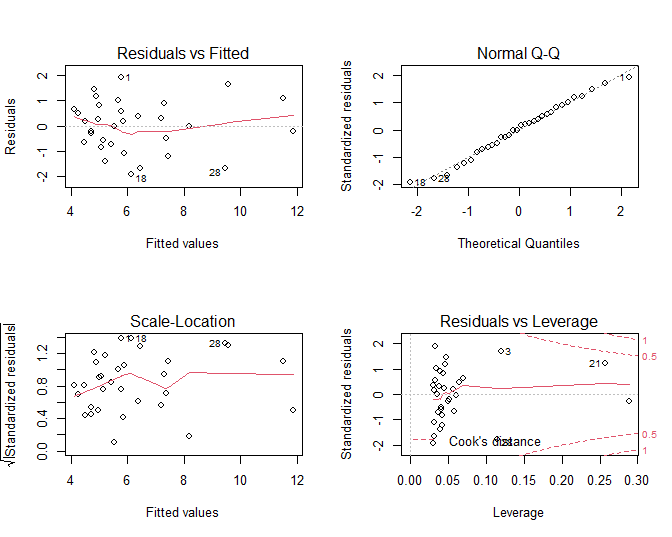
Figuur 32: Diagnostische plots voor het lineair model voor log2-S100A8 expressie in functie van de log2-ESR1.
Na log-transformatie zijn alle voorwaarden voldaan en kunnen we overgaan tot statistische besluitvorming en interpretatie van de modelparameters.
summary(lm2)
##
## Call:
## lm(formula = log2S100A8 ~ log2ESR1, data = brca)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1.94279 -0.66537 0.08124 0.68468 1.92714
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 23.401 1.603 14.60 3.57e-15 ***
## log2ESR1 -1.615 0.150 -10.76 8.07e-12 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.026 on 30 degrees of freedom
## Multiple R-squared: 0.7942, Adjusted R-squared: 0.7874
## F-statistic: 115.8 on 1 and 30 DF, p-value: 8.07e-12
confint(lm2)
## 2.5 % 97.5 %
## (Intercept) 20.128645 26.674023
## log2ESR1 -1.921047 -1.308185
Er is een extreem significante negatieve associatie tussen de S100A8 en ESR1 genexpressie (\(p<<0.001\)).