If the response is a factor containing more than two levels, then the svm()
function will perform multi-class classification using the one-versus-one approach.
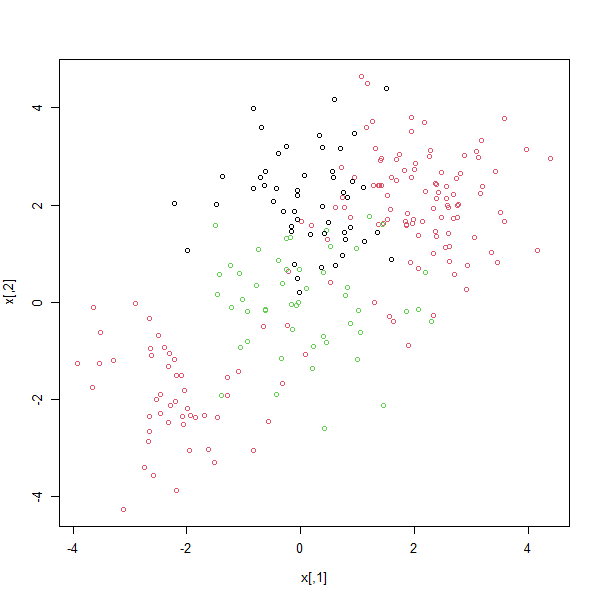
We explore that setting here by generating a third class of observations.
set.seed(1)
x <- rbind(x, matrix(rnorm(50 * 2), ncol = 2))
y <- c(y, rep(0, 50))
x[y == 0, 2] = x[y == 0, 2] + 2
dat <- data.frame(x = x, y = as.factor(y))
par(mfrow = c(1, 1))
plot(x, col = (y + 1))
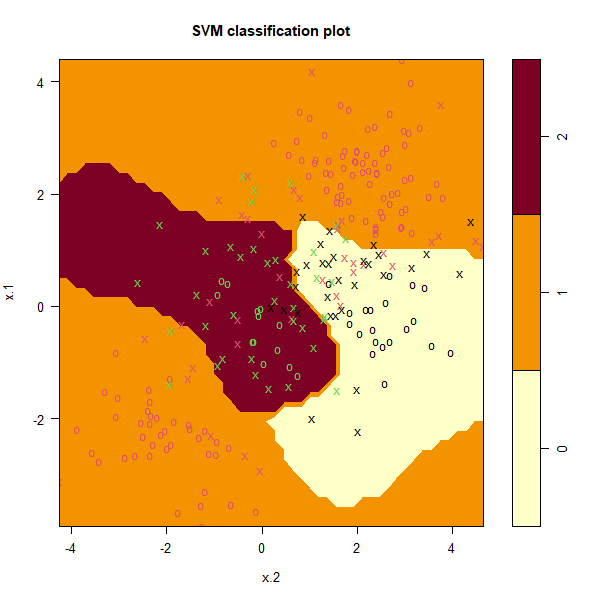
svmfit <- svm(y ~ ., data = dat, kernel = "radial", cost = 10, gamma = 1)
plot(svmfit, dat)
The e1071 library can also be used to perform support vector regression,
if the response vector that is passed in to svm() is numerical rather than a
factor.
Questions
MC1: Which of these statements are true? (only one correct answer)
1) By default multi-class SVM classification uses a one-versus-all approach
2) In one-versus-one classification, we will need to train \(k(k-1)/2\) classifiers (with \(k\) being the number of classes)
3) In one-versus-all classification, every classifiers will have no class imbalance
4) In one-versus-one classification, every classifier will use the entire data set to train