After the extraction of the tweets and the mining of the data, it is time to estimate the importance of the words using random forest.
p_load(randomForest)
rf <- randomForest(x,y, importance=TRUE)
The following code block extracts the feature importance.
imp <- importance(rf) %>%
as_tibble(., rownames = 'Features') %>%
arrange(desc(`%IncMSE`))
imp
Features `%IncMSE` IncNodePurity
1 report 0.9 1.75
2 appleevent 8.39 1.46
3 indie 6.79 0.393
4 gamedev 6.64 5.85
5 hosted 6.05 0.335
6 indiegame 5.83 4.53
7 amp 5.42 4.38
8 iphonepro 5.42 0.963
9 due 4.46 0.773
10 day 3.38 0.718
The variable importance is plotted.
varImpPlot(rf,type=1)
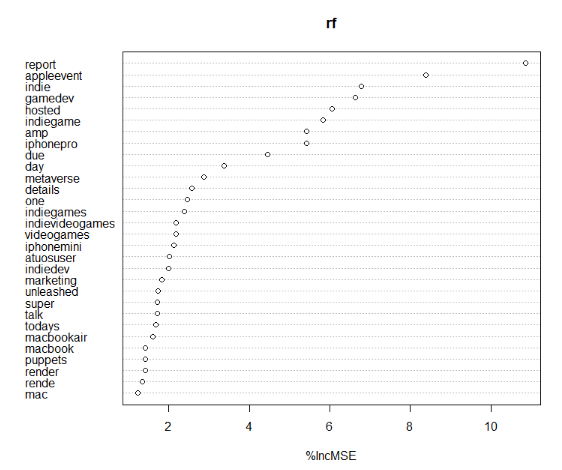
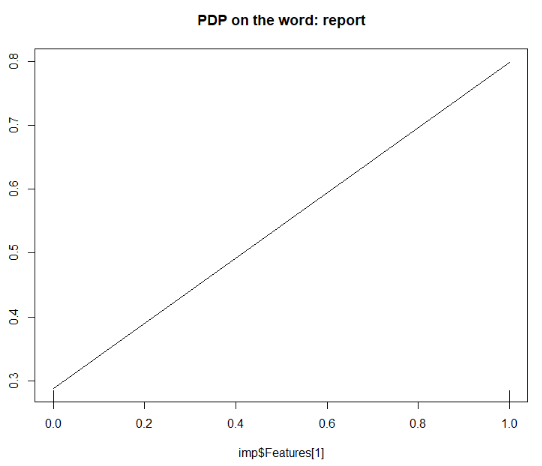
It can be interesting to use scatterplots or partial plots to determine which important words should or should not be used.
partialPlot(rf,as.data.frame(x),imp$Features[1],
main = paste('PDP on the word:',imp$Features[1]))
Exercise
Consider the tweets about #PS5 from the exercise before. Build a random forest model and store this in rf. The random forest model needs to have 50 trees. Then, extract the feature importance and store this in feature_imp.
To download the document term matrix as a tibble click: here1
To download the retweet count click: here2
Assume that:
- The randomForest library has been loaded.
- The document term matrix as a tibble has been stored in
xand has been loaded. - The retweet count has been stored in
yand has been loaded.