Evolutie van het aantal personenwagens per brandstofsoort in België
Gegevens
Voor deze oefening werken we met cijfermateriaal afkomstig van de Belgische overheid, meer bepaald Statbel (https://statbel.fgov.be/nl/themas/mobiliteit/verkeer/voertuigenpark#news).
Per jaar beschikken we over het aantal personenwagens per brandstofsoort in België. De gegevens beslaan de periode van 2007 tot en met 2025.
De gegevens zijn samengebracht in het bestand "veh_parc_nl.csv". Als voorbeeld zie je hieronder de eerste regels van het bestand.

De kolommen in het bestand zijn als volgt:
- brandstof: de brandstofsoort, één van volgende mogelijkheden: Benzine, Diesel, Gas, Elektriciteit of Hybride
- jaar: het jaar van de telling
- personenwagens: het aantal personenwagens van deze brandstofsoort in dat jaar (geheel getal met de spatie als scheidingsteken voor de duizentallen)
Opgelet! Er zijn niet voor elke jaar voor alle brandstofsoorten gegevens beschikbaar in het bestand.
Databestand
Het bestand is beschikbaar in het working directory van Dodona. Als je de oefening echter lokaal wilt maken (in PyCharm of in een Jupyter Notebook), dan moet je het bestand downloaden en bewaren in dezelfde map als je .py of .ipynb bestand.
Je kan het bestand hier downloaden: veh_parc_nl.csv
Opgave
-
aantal_wagens
Schrijf een functie aantal_wagens met één argument: de naam van een brandstofsoort (string)
De functie leest het bestand "veh_parc_nl.csv" in en retourneert lijst met het aantal personenwagens per jaar voor de opgegeven brandstofsoort. De lijst moet altijd 19 elementen bevatten, waarbij het eerste het aantal wagens is voor het jaar 2007 en het laatste voor het jaar 2025. Als er voor dit brandstoftype een bepaald jaartal geen gegevens beschikbaar zijn, vul je dat jaar in met "NB".
Voorbeelden
>>> aantal_wagens("Benzine") [2247799, 2161807, 2092472, 2035578, 2005481, 1981861, 1992418, 2029688, 2091327, 2199038, 2335349, 2518942, 2709604, 2843903, 2951770, 3021102, 3096253, 3132607, 3136259]
>>> aantal_wagens("Hybride") ['NB', 'NB', 'NB', 'NB', 'NB', 'NB', 'NB', 23444, 32151, 44364, 63740, 87012, 110984, 154807, 258916, 375107, 537817, 710687, 846354]
-
glg
Schrijf een functie glg (gewogen lopend gemiddelde) met drie argumenten: een brandstofsoort (string), een jaartal (int) en een strikt positief geheel getal n (int)
De functie haalt de gegevens voor de opgegeven brandstofsoort op uit het databestand en berekent het gewogen gemiddelde van het aantal wagens voor de opgegeven brandstofsoort over de laatste n jaar(en) tot en met het opgegeven jaartal.
Het gewogen gemiddelde wordt berekend met de gewichten: 1, 2, 3, ..., n voor de respectievelijke jaren. Het meest recente jaar krijgt dus gewicht n (dus dat aantal wagens wordt vermenigvuldigd met n) en de oudste jaar krijgt gewicht 1. De som van de gewogen aantallen wordt gedeeld door de som van de gewichten in plaats van door n zoals bij een gewoon gemiddelde.
Concreet betekent dit dat voor een gegeven brandstofsoort, jaartal = t het gewogen lopend gemiddelde GLG over n jaar wordt berekend als:
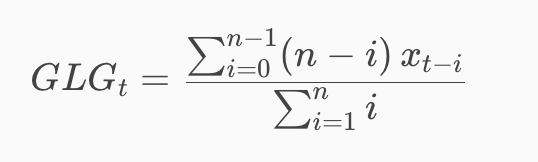
waarbij xt-i het aantal personenwagens is voor het jaar t-i van die brandstofsoort en i het gewicht van dat jaar.
Als niet alle gegevens beschikbaar zijn om het gewogen lopend gemiddelde te berekenen, retourneert de functie de string "NB".
Het GLG wordt afgerond naar een geheel getal volgens de klassieke wiskundige methode. Dit wijkt af van de standaard afronding in Python. Concreet betekent dit dat positieve waarden met decimaal .5 naar boven worden afgerond (bv. 12.5 → 13) en niet naar het dichtsbijzijnde even getal.
Voorbeelden
>>> glg("Elektriciteit", 2014, 2) 1501
>>> lopend_gemiddelde("Elektriciteit", 2026, 3) "NB"