Optical character recognition (OCR) is een techniek die kan gebruikt worden om ingescande afbeeldingen van handgeschreven, getypte of afgedrukte tekst om te zetten naar ASCII-tekst die leesbaar is voor een computer. Deze techniek wordt vaak gebruikt om afgedrukte teksten te digitaliseren zodat men ze elektronisch kan doorzoeken, compacter kan opslaan, online kan weergeven, of ze automatisch kan laten vertalen of voorlezen door een computer. OCR vormt een onderzoeksdomein binnen de patroonherkenning, artificiële intelligentie en computervisualisatie.
In deze opgave werken we met tekstbestanden, waarvan de regels een aantal handgeschreven karakters voorstellen. Het handschrift staat telkens in een lettertype dat voldoet aan volgende voorwaarden:
alle regels hebben dezelfde lengte (inclusief spaties)
gelijke handgeschreven karakters worden steeds op dezelfde manier weergegeven
verschillende handgeschreven karakters worden nooit op dezelfde manier weergegeven
de voorstelling van een handgeschreven karakter bevat nooit lege kolommen
tussen twee opeenvolgende handgeschreven karakters staan één of meer lege kolommen
voor het eerste en na het laatste handgeschreven karakter staan nul of meer lege kolommen
Een lege kolom is een kolom van de regels met handgeschreven tekst die enkel bestaat uit spaties.
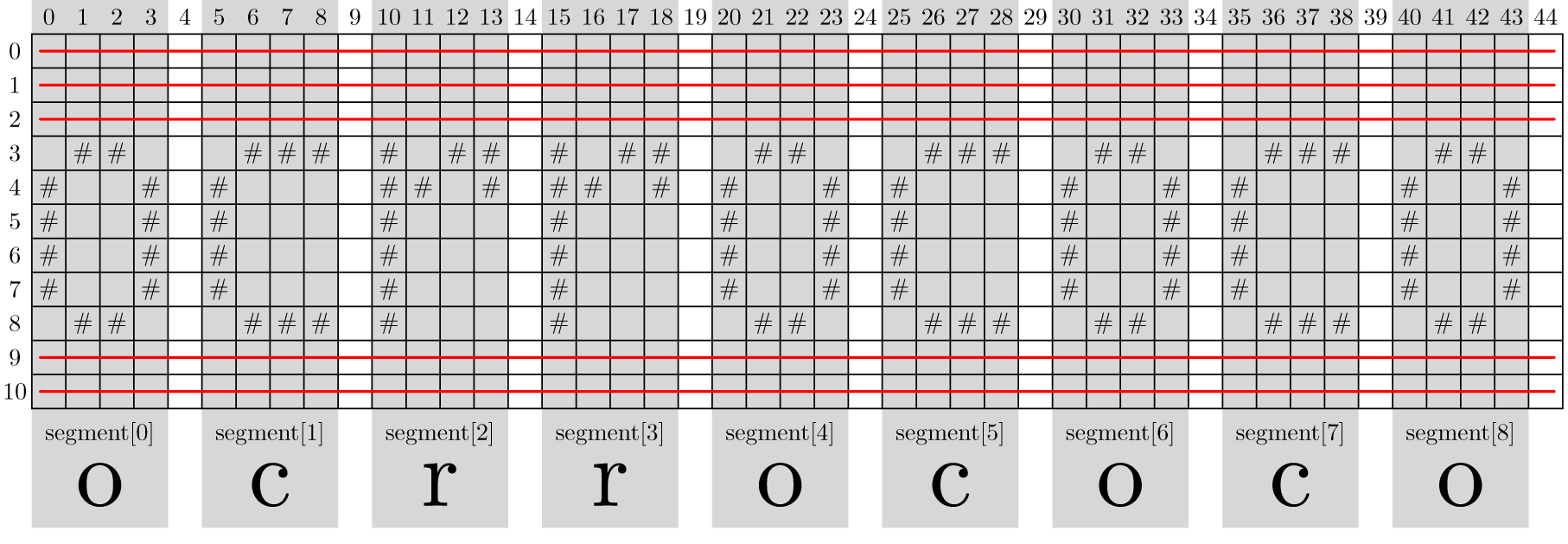
Hieronder wordt bijvoorbeeld de inhoud weergegeven van een tekstbestand dat een handgeschreven versie van de letters ocrrococo bevat. Klik hier om een grafische voorstelling van de segmentatie van dit tekstbestand te bekijken. Hierbij worden de segmenten aangegeven met een donkergrijze achtergrond, en worden de regels die niet opgenomen worden in de stringvoorstelling van segmenten met een rode lijn doorstreept.
## ### # ## # ## ## ### ## ### ##
# # # ## # ## # # # # # # # # #
# # # # # # # # # # # # #
# # # # # # # # # # # # #
# # # # # # # # # # # # #
## ### # # ## ### ## ### ##
De opgave bestaat erin om de inhoud van het tekstbestand om te zetten naar de corresponderende reeks ASCII karakters. Hiervoor ga je als volgt te werk:
OCR start vaak met het segmenteren van de handgeschreven tekst, waarbij het handschrift wordt opgedeeld in individuele handgeschreven karakters (in deze context segmenten genoemd). Schrijf daarvoor een functie segmentatie waaraan de locatie van een tekstbestand met handgeschreven tekst als argument moet doorgegeven worden. De functie moet een lijst teruggeven met alle segmenten die in het tekstbestand voorkomen. Daarbij wordt een segment gevormd door één of meer opeenvolgende niet-lege kolommen die tussen twee lege kolommen ingesloten zitten. Ook opeenvolgende niet-lege kolommen vooraan of achteraan het tekstbestand vormen een segment. Een segment wordt voorgesteld als een string door alle rijen van het segment achter elkaar te zetten en van elkaar te scheiden door newline karakters. Rijen waarop in het oorspronkelijke tekstbestand alle karakters spaties zijn (niet enkel binnen het segment, maar over de volledige regel), worden niet opgenomen in de stringvoorstelling van het segment. Het is de stringvoorstelling van een segment die moet opgenomen worden in de lijst die door de functie wordt teruggegeven.
Gebruik de functie segmentatie om een functie OCR te schrijven die kan gebruikt worden om een handgeschreven tekst om te zetten naar de corresponderende ASCII karakters. De handgeschreven tekst zit opgeslagen in een tekstbestand, waarvan de locatie als argument aan de functie moet doorgegeven worden. Het deel van de bestandslocatie voor het eerste punt vormt een woord, waarvan de ASCII karakters meteen ook de beginkarakters vormen van de handgeschreven tekst. De bestandsnaam ocr.txt levert dan bijvoorbeeld het woord ocr op. De resterende karakters van de handgeschreven tekst komen allemaal ook in het woord voor. De functie moet een string teruggeven die de ASCII karakters bevat die corresponderen met het woord dat bestaat uit de resterende handgeschreven karakters.
Bij onderstaande voorbeeldsessie gaan we ervan uit dat de tekstbestanden ocr.txt, sportmannen.txt en romanheld.txt zich in de huidige directory bevinden.
>>> segment = segmentatie('ocr.txt')
>>> segment[0]
' ## \\n# #\\n# #\\n# #\\n# #\\n ## '
>>> print(segment[0])
##
# #
# #
# #
# #
##
>>> print(segment[1])
###
#
#
#
#
###
>>> print(segment[2])
# ##
## #
#
#
#
#
>>> print(segment[3])
# ##
## #
#
#
#
#
>>> print(segment[-1])
##
# #
# #
# #
# #
##
>>> OCR('ocr.txt')
'rococo'
>>> OCR('sportmannen.txt')
'marmer'
>>> OCR('romanheld.txt')
'emerald'
Klik op onderstaande links om een grafische voorstelling van de segmentatie van de tekstbestanden te bekijken. Hierbij worden de segmenten aangegeven met een donkergrijze achtergrond, en worden de regels die niet opgenomen worden in de stringvoorstelling van segmenten met een rode lijn doorstreept.
{kind=link}
{kind=link}
{kind=link}