Gemiddelde en variantie
Het gemiddelde of de verwachte waarde is
\[\int \limits_{x \in \Omega} x f(x) dx.\]Voor de normale distributie
\[\int \limits_{-\infty}^{+\infty} x f(x) dx = \mu.\]De parameter \(\mu\) is dus het gemiddelde van een Normaal verdeelde veranderlijke X de populatie.
De variance \(E[(X-E[X])^2]\)
\[\int \limits_{x \in \Omega} (x-E[X])^2 f(x) dx\]Voor de normale distributie bekomen we
\[\int \limits_{-\infty}^{+\infty} (x-\mu)^2 f(x) dx = \sigma^2\]De parameter \(\sigma^2\) is dus de variantie van een Normaal verdeelde veranderlijke X in de populatie.
Het is vaak moeilijk om de variantie te interpreteren gezien ze niet in de zelfde eenheden staat als het gemiddelde. Daarom werken we vaak met de standaardafwijking (SD):
\[SD=\sqrt{E[(X-E[X])^2]}\]De standaardafwijking voor de normale distributie, \(\sigma\) heeft de interessante interpretatie dat ongeveer 68% van de populatie een waarde heeft voor de karakteristiek X binnen het interval van 1 standaardafwijking(\(\sigma\)) rond het gemiddelde:
\[P(\mu-\sigma < X < \mu + \sigma) \approx 0.68\]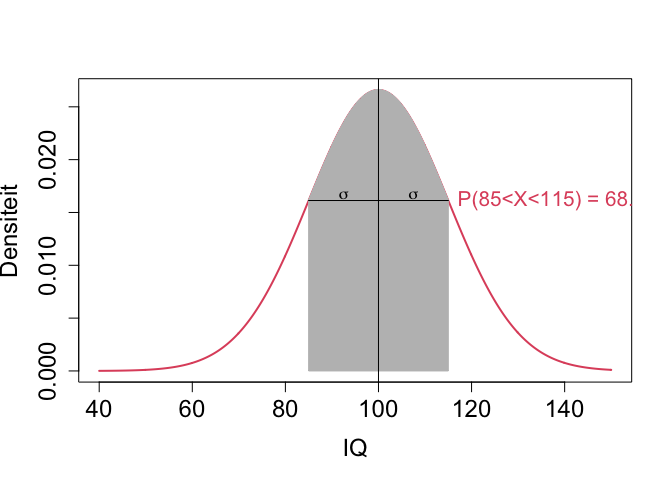
Voor Normaal verdeelde toevallig veranderlijken heeft ongeveer 95% van de subjecten in de populatie een waarde die binnen twee standaardafwijkingen (\(2 \sigma\)) ligt van het gemiddelde.
\[P[\mu - 2 \sigma < X < \mu + 2 \sigma]\approx 0.95\]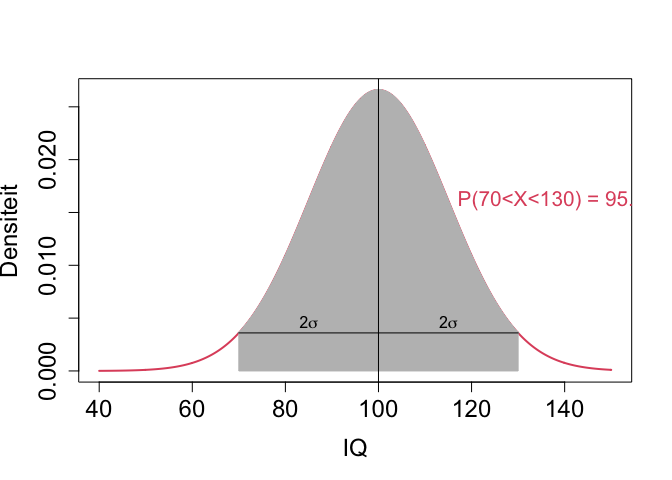
Deze intervallen worden ook wel een referentie interval genoemd.